Lectures are often static objects. The size of the audience, time constraints, and the need for conference organisers to keep some editorial control make sessions mostly about transmission (“this is going to be just me speaking now”) rather than engagement (“I’ll guide a discussion through which you’ll learn”).
Although the audience size and format are often quoted, the traditional static nature of lectures was also connected, and in no small measure, to the way visual material was prepared. Slides (of the old kind, not digital ones) were expensive things you’d have to plan very carefully. Object needed to be photographed (expensive and slow), and slides developed and mounted (ditto). If you wanted text on slides, you’d need to prepare the text separately and shoot the slide on a rostrum (yet more cost and delay). Once lectures were delivered, they would either remain in the memories and notes of attendees, or be published as pamphlets or transcripts, usually omitting the images. The situation for lectures that are preserved as podcasts is similar.
My oldest lecture with PDF slides is from early 1999. I still remember the elation of being liberated from film. Scanners and Acrobat made planning of versions for different lengths and audiences orders of magnitude easier, and eliminated many costs. And working with text in slides became trivial. Yet, while the speed and flexibility of building lectures improved dramatically, the format of the lectures changed very little. From the point of view of the audience, the only difference is that transitions between slides were much faster and smoother, and that it was possible to linger on a single slide for many minutes, since doing this with a transparency risked burning the slide. Regardless, the transition to PDFs did not change the structure of the lecture from a somewhat rigid narrative punctuated by images.
The gradual adoption of presentation software like Keynote and PowerPoint for public lectures (because teaching environments are a different case; another blog post) precipitated a shift to lectures being structured as sequences of images with annotations attached to them. The ease with which presentation apps allowed tree-style outlines to be built or imported strengthened this trend as a way to compose a lecture.
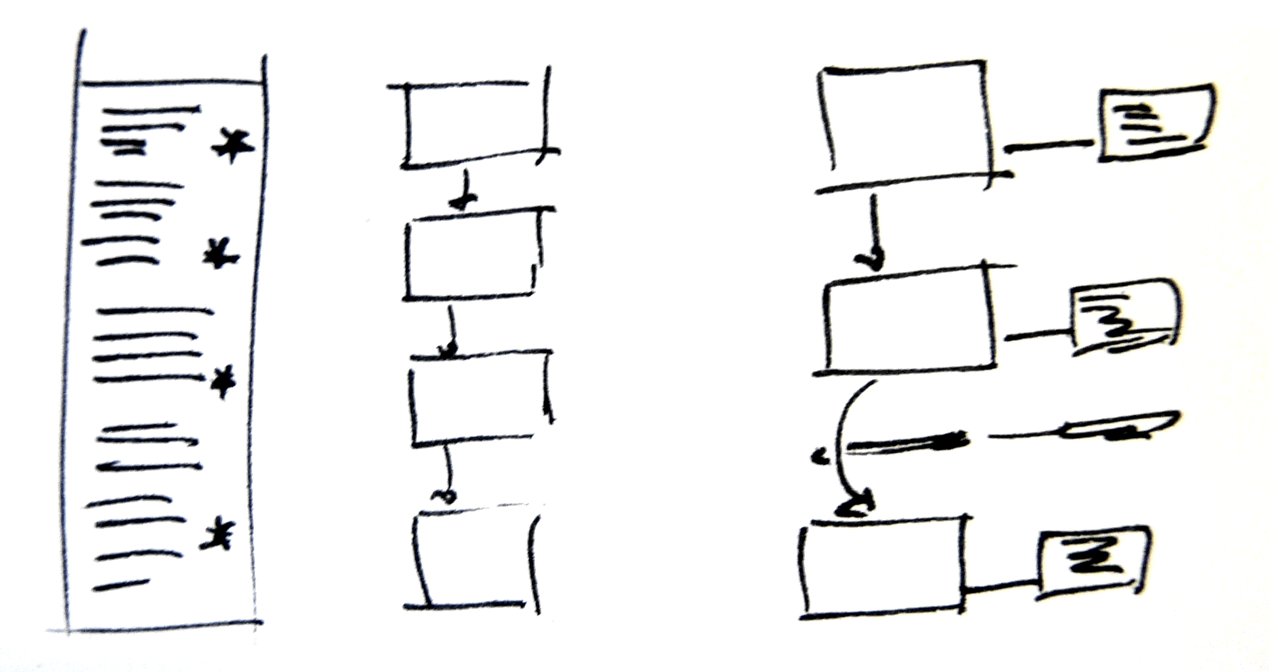
For the speaker this means a greater number of slides, since each point in the narrative needs a slide simply to exist, let alone be elaborated. For the audience this is a Good Thing, since it adds a visual dimension to explanations that would otherwise be left to words alone. This is pretty much where we are today; tools like Prezi do not shift from this model. (Sliderocket offers collaborative functions and tracking elements, but these are intended for internal teams, not public engagement.)
But whereas lecture composition and delivery has (sort-of, if you’re in a generous mood) kept up with developments in content authoring, it has not progressed much in adding value to a lecture after it has been captured. We have acceptable records of what was shown and said at the time of delivery, mostly by sticking a camera in the aisle so that both the speaker and the slides are in the frame, or by splicing a talking head in a frame that is mostly taken over by the slide, or by trying to switch between the two. From the speaker’s point of view, the best you can hope for is a separate feed for the audio from the microphone, instead of the camera’s own.

Both these options exist in silos on YouTube or Vimeo, mostly. Although comments on the video’s page are possible, these stick on the page of the video, and by default refer to the whole: comments cannot link explicitly to a point in the stream.
Depending on the how the speaker uses the lecture slides, posting the deck on Speakerdeck or Slideshare may be anything from very useful to utterly confusing. Some speakers use their slides to illustrate points and punctuate their talk: they conceive the narrative as a combination of verbal and visual content in sync. But these decks tend to make little sense on their own, since the speakers’ explanations and bridging sentences are missing. (A “bridging sentence” spans two slides, and is used to join the transition to a new visual message with the verbal narrative.)

On the other hand, speakers that use their slides as a record of the argument trade a less engaging presentation for a more useful record of the talk’s key points. This category of decks spans anything from a few sentences on a slide, like this:

… to semantic soups that make your head spin and scream “FFS, what where you thinking?!”
Both video capture and deck publishing are undeniably useful. But they are closed objects, with very limited scope for interaction and cross-referencing. Especially in non-academic circles, where a talk is not an exposition of a scholarly paper, the video or slide deck may be the only “text”. Speakers may transcribe their points in blog posts, but then the text in the blog post encapsulates the ideas, not the talk itself.
It is also possible to take a deck as a starting point, and annotate it in a way that it becomes a more-or-less self-contained text. I tried this with my latest talk on the relationship of tools and innovation, delivered in Warsaw a week ago. The slides went from 67 to 93, and the word count from 590 to 1,330. This is an experiment to compare the reach of this deck with other decks that were uploaded within minutes of delivery, warts n’ all.

This was the slide that I added immediately after, in the uploaded deck:

In some slides, I added text on the original slides:

So far so good?
But a good lecture generates commentary, both during its delivery and after it has been published. While a lecture is being delivered, things are happening: people are reporting, commenting, expanding, and even making old-style notes:

Services like Eventifier or Storify can build a partial record of an event after the fact, but they are not optimised for the smaller scale of a single lecture. And they primarily compile what’s already out there, without the functionality to edit the results or comment on specific parts. Even so, these results are not linked back to the lectures themselves, let alone the moment the tweets were posted or the images taken.
Worse, if someone writes a coherent and engaged response to a talk (like John D. Berry did for my Ampersand talk) this is isolated from the source, whether it exists on video or slide deck. Or any other part of the discussion the talk might have generated, for that matter.
Not very “social”, then. Events that are, in essence, starting points for discussions and catalysts for ideas, become fragmented, flat sets of disconnected objects.
So, what then?
A good lecture is a story with convincing arguments. A great lecture will leave the audience with new ideas, and set off ripples of discussions and further “texts”. Ideally, all these things are connected, and become part of a collaborative document. This is what citations do in the academic world, and what links do online. It seems paradoxical that we have easy ways to connect verbal hiccups, but do not have an easy, robust, and open way to link within lectures. Considering the effort that a good lecture encapsulates, this is pretty wasteful.
I don’t know if this platform exists, but here’s my back-of-an-envelope model for a slide deck viewer; obviously only one slide (and the discussion it generates) are viewable at a time:
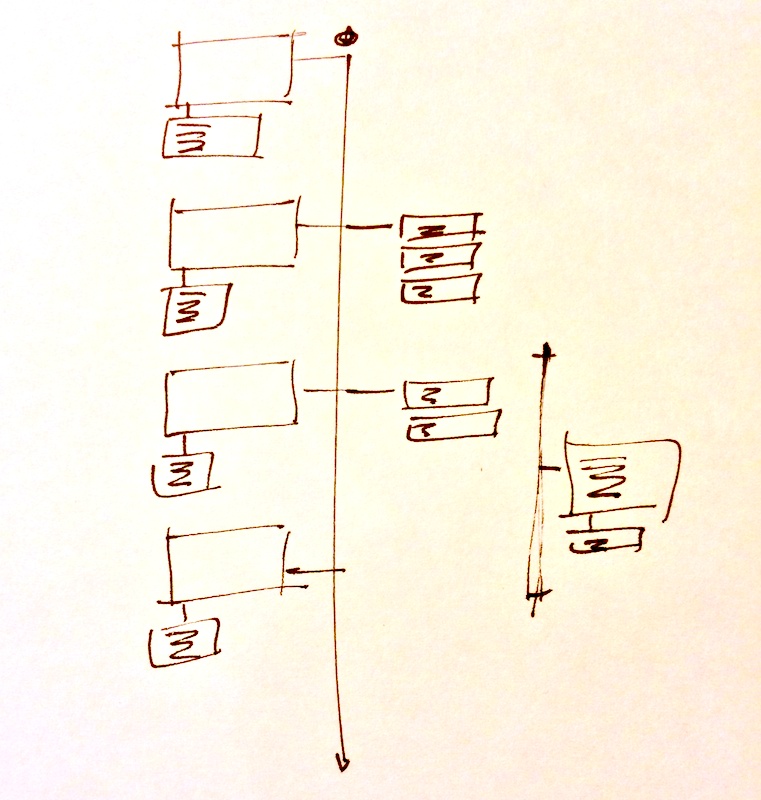
For this to work every slide would need to have its own URL, but that should be really easy. (So, my slides above could have addresses like
speakerdeck.com/gerryleonidas/2013/11/23/tti/slide28
and a comment
speakerdeck.com/gerryleonidas/2013/11/23/tti/slide28#http://twitter.com/username/status/01234567890123456789
For a video talk, something like this:
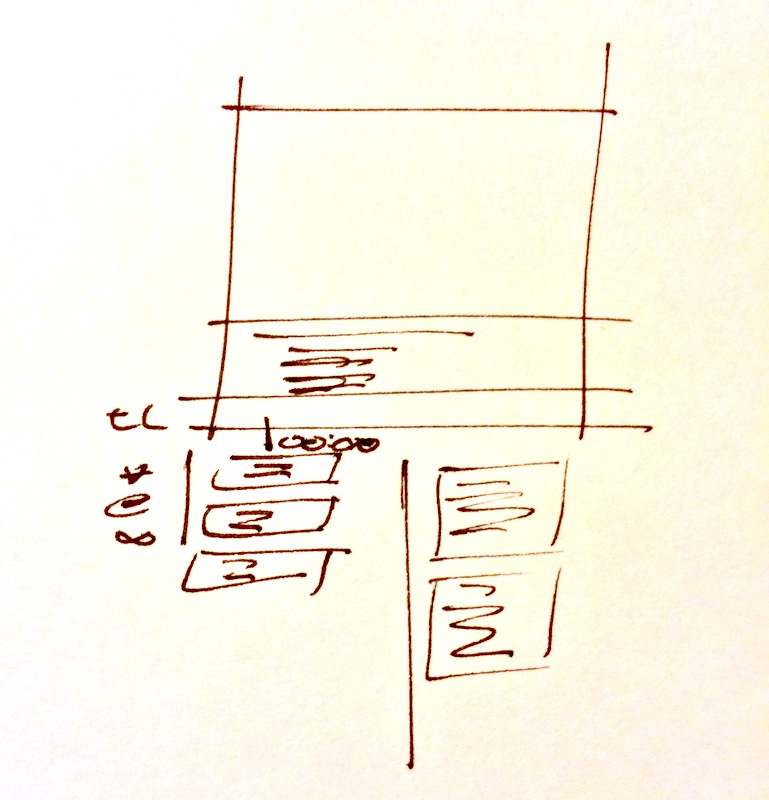
If there’s an easy way to link to a specific time point in a video stream from within a comment or a tweet, and collect all that together, I’ve missed it. But I’d like to be able to link to
vimeo.com/clearleft/2013/06/28/ampersand/gerryleonidas/20-45/.
You get the picture.
Any takers, internet?